My Blog.
-
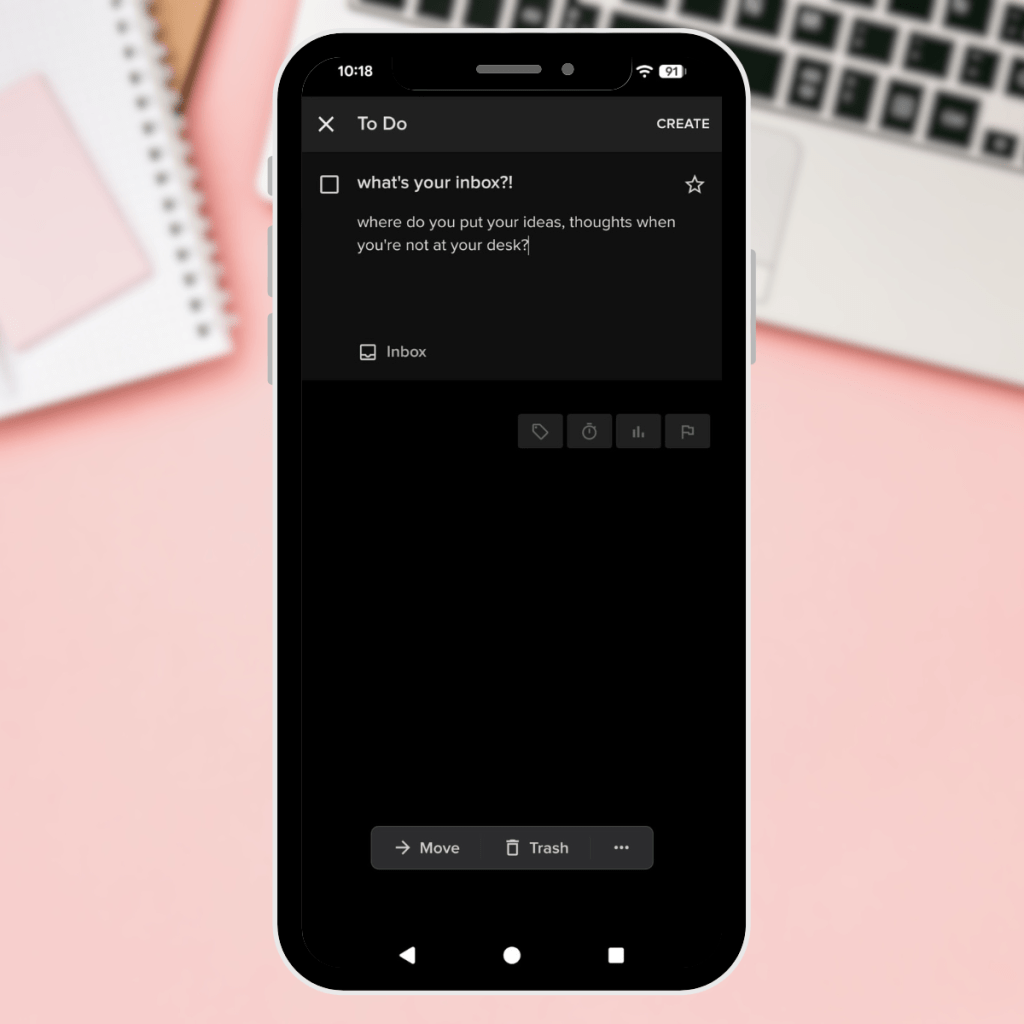
What’s your “inbox”?
Where do you put your thoughts and ideas when you’re out at dinner, about to fall asleep, having a coffee? Things that I have discovered DO NOT work well as an inbox: The thing that unlocked this for meore than one inbox is fine, just keep it limited to very few places that you can…
-

365 days at a tech start up
A year ago, I joined Danu Insights, a tech startup based in Edinburgh. Here are 5 learnings (and 1 hot take) from my first year, not just for startups, but any fast-paced environment. Job descriptions are inspo onlyBe realistic that you are likely not just gonna do the things mentioned in your job specs. I…
-

Single vs Multi-objective Optimisation
Most real decisions have at least two goals. Decrease cost and increase performance, increase yield and purity, or quicker and healthier in the case of your dinner. How you optimise for these goals can fundamentally change the answer you end up with. Take a simple everyday problem: deciding what to cook for dinner, ideally something…
-

Books of 2025
Welcome to the sixth instalment of my annual book review! In 2025, I consumed a total of 18 books; and for the first time ever, this includes five audio books! Together they span precisely 6,800 pages – a 17% drop compared to last year. 2025 saw an exciting mix of fiction, non-fiction, and memoirs, so…
-

Board Games of 2025
Another year, another board game roundup! 2025 has been a great year for me, board-game wise: many two-player games, different groups of friends with different board game preferences, even up to six players routinely. I also got to go to the Tabletop Scotland convention this year, where I spent a small fortune on second hand…
-

2nd poster prize at RSS
In September 2025 I attended the Royal Statistical Society conference in Edinburgh. It was a good chance to connect with colleagues, catch up with friends, make new ones, and even win a prize! What I particularly enjoyed about this conference was the fact that it covered everything from theory to applications and academia to industry.…
-

Smart data for smarter tourism
I’m delighted that our report on tourism and transportation in Edinburgh is now publicly available. The this pilot was led by Smart Data Foundry in partnership with Capital City Partnership, TravelTech for Scotland, and Workforce Mobility. What I found most rewarding about this work was that we didn’t collect any new data. Instead, we brought…
-

Featured Profile
I was recently profiled by the Academy for the Mathematical Sciences as part of their Maths Can Take You Anywhere showcase, which features 23 mathematicians across the UK. The initiative celebrates the many different facets that a career in the mathematical sciences can take, from academia and industry to policy and beyond. My own journey…
-

Published Paper!
My paper based on my PhD research, “Estimating Product Cannibalisation in Wholesale Using Multivariate Hawkes Processes with Inhibition”, has been published in the Annals of Applied Statistics. This work addresses challenges in understanding how closely related products may compete with one another in a wholesale setting. In the paper, we propose a novel modelling framework…
Got any recommendations?
